Informe  sobre el voto electrónico
sobre el voto electrónico



Los protocolos anteriormente presentados funcionan en el cumplimiento de los requisitos de seguridad, en cierta medida y dentro de las capacidades que se han mencionado en la descripción, siempre que confiemos en que los agentes que ejecutan el protocolo son honestos. Ésta, por ejemplo, es una de las limitaciones del voto electrónico en general, y también del voto por internet: en el momento de emitir el voto, el que ejecuta el protocolo no es el votante, sino el software de voto. ¿Cómo podemos saber que hace lo que el votante quiere?
Lo mismo sucede con el proceso de recuento. Como los votos son digitales, no los cuentan los miembros de la mesa electoral, como en una elección tradicional, sino un software de recuento. En el caso de utilizar técnicas de anonimización en la fase de recuento, como el recuento homomórfico o el mixing, el software no solo está a cargo de contar votos, sino de hacer un procesado previo (ya sea la operación de los votos cifrados o el mixing) y descifrarlos para poder contar. Entonces, es importante poseer alguna herramienta que permita auditar este código para garantizar que durante todas estas operaciones no se modifiquen los votos o el resultado obtenido del recuento.
Algunas medidas que se pueden aplicar son: realizar una auditoría del código para asegurar que el funcionamiento es el esperado, hacer una compilación pública (lo que se conoce como trusted build ) del código auditado, y garantizar que este mismo código es el que se ejecuta, usando código firmado digitalmente, boot CDs para asegurar que el código se arranca en un sistema limpio (sin virus o códigos maliciosos), o herramientas de auditoría del software en ejecución. De estas últimas, las herramientas que escanean los ficheros ejecutables y de configuración para detectar cualquier modificación son muy populares (Tripwire, AIDE), pero presentan la siguiente cuestión: ¿Quién fue primero, el huevo o la gallina? Si utilizo una herramienta para escanear los ficheros ejecutables del sistema y comparar que coinciden con los auditados, quién asegura que esta herramienta no ha sido modificada, es más, estas herramientas pueden escanear los ficheros ejecutables, pero no ven cuáles son los que efectivamente se acaban ejecutando. ¿De qué nos sirve comprobar que el software bueno está instalado si después se ejecuta otro? Una mejora de estos sistemas de escaneo es el Integrity Measure Architecture (IMA), una herramienta presente a partir de la versión 6 de las distribuciones RedHat y CentOS de Linux, que genera un registro (un fingerprint) de cada fichero antes de que se ejecute. Así se puede conocer el código ejecutado y no solo el instalado. Esta herramienta puede usarse conjuntamente con un TPM (Trusted Platform Module [5]), un chip hardware criptográfico propuesto por el Trusted Computing Group [6] y presente hoy en día en muchos ordenadores, que, entre otras cosas, almacena de forma segura registros o fingerprints de los valores de los procesos ejecutados en un ordenador, desde que se pone en marcha la BIOS hasta que se arranca el sistema operativo, lo que permite mantener la cadena de confianza hasta el inicio de la herramienta IMA. La IMA además se puede configurar para que almacene los fingerprints que genera en los registros seguros del TPM, para evitar modificaciones o borrados.
Como hemos visto, auditar la autenticidad del software que se ejecuta no es trivial. Y aún menos cuando el software se ejecuta en ordenadores remotos no controlados, como pueden ser los de los votantes. El cliente de votación puede verse afectado por virus o malware que esté infectando el dispositivo del votante, de forma que cambie las opciones escogidas por éste y envíe al servidor de voto un voto que contiene otras. El votante, incluso pudiendo ver la comunicación entre su dispositivo y el servidor, no podría saber si lo que se está enviando coincide con lo que ha elegido, ya que el voto va cifrado.
Por ello, una evolución que se ha experimentado recientemente en el voto por Internet, es la demanda de verificación, que consiste en que los votantes, auditores y otros observadores externos, sean capaces de poder verificar que el software de voto funciona de forma correcta. Así se puede asegurar que los resultados de la elección son correctos y representan la intención de voto de los votantes, sin poner en riesgo la privacidad.
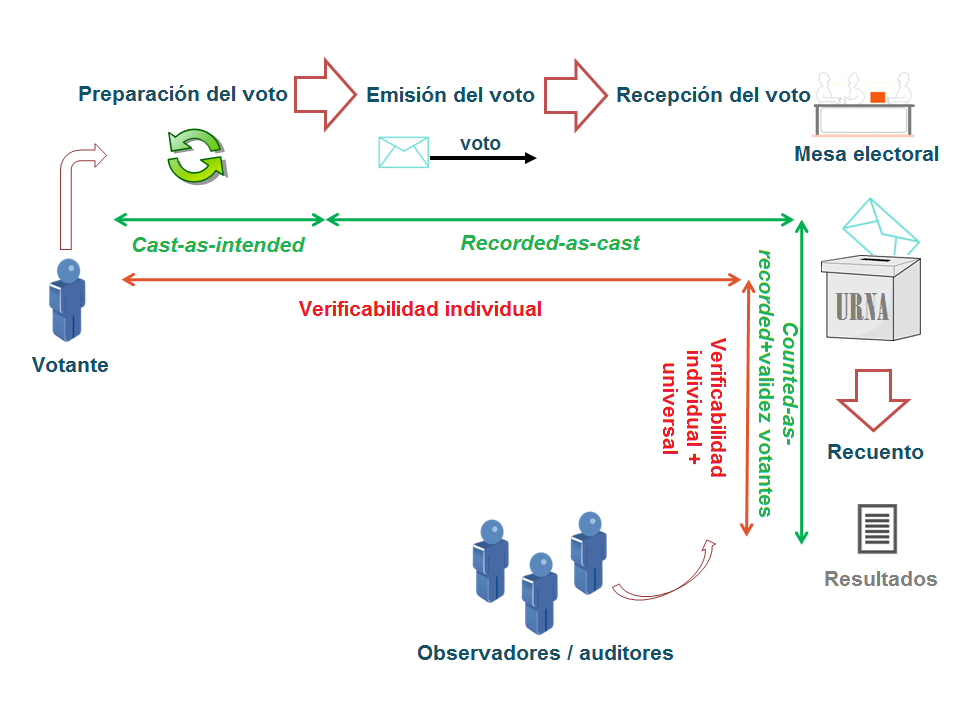
Hemos visto que hay dos problemáticas básicas: que el votante pueda asegurar que el voto que emite representa sus opciones, y que se pueda auditar el proceso de anonimización de los votos y recuento. De los requisitos de seguridad del voto electrónico podemos extraer otras, como poder verificar que sólo se cuenta un voto por votante, y que estos votos han sido emitidos por votantes válidos. Existen varias clasificaciones según el tipo de verificabilidad (ver figura 10):
Una característica muy buena de la criptografía es que está basada en matemáticas y las matemáticas no mienten. Quizás no pueda asegurarse que un software específico es auténtico o se ejecuta sin interferencia externa, pero podemos forzar a este software a hacer pruebas criptográficas que demuestren que las operaciones que hace las hace correctamente, sin que pueda mentir. A continuación explicaremos algunos protocolos criptográficos de votación y herramientas que aportan verificabilidad al proceso.
Existen principalmente dos tipos de métodos para realizar esta verificación: desafiar al cliente de votación o utilizar códigos de retorno.
Como hemos introducido en la sección 1.5, el cliente de Votación consiste en el software que se ejecuta en el dispositivo del votante. Este cliente normalmente se encarga de presentar al votante las opciones de voto, recoger sus selecciones y cifrar y firmar el voto antes de enviarlo al servidor remoto de votación.
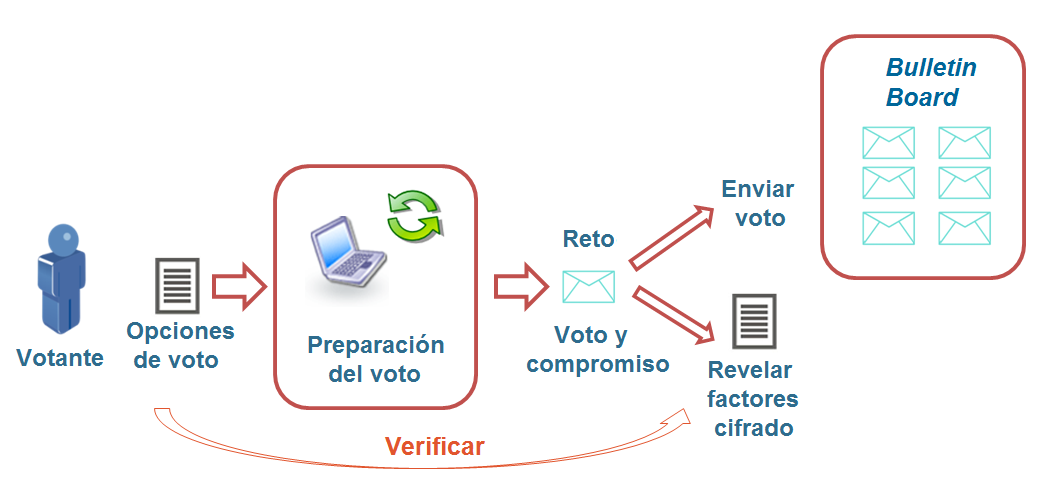
El proceso de verificación consiste en seguir los pasos de la aplicación de voto hasta que las opciones de voto elegidas son cifradas por el cliente de votación, y después tener la oportunidad de pedir al cliente que abra el voto cifrado para ver que lo que había dentro y se iba a enviar era efectivamente lo que se había elegido (ver figura 11). Este método fue propuesto en principio por Josh Benaloh [15] y se utiliza en el sistema de voto por Internet Helios [11, 12], un sistema que empezó como una prueba académica y que se ha utilizado en muchas elecciones universitarias y cada vez gana más atención. La idea es que una vez ha cifrado el voto, el cliente de votación se compromete mostrando al votante un hash del valor del voto cifrado. Con comprometerse, queremos decir que el cliente de votación da un dato referente al voto cifrado (en este caso, el valor de su hash) de forma que más tarde no puede retractarse y decir que el valor del voto cifrado era otro. Antes de enviar el voto, el votante tiene la oportunidad de auditarlo y pedir al cliente de voto que muestre los valores con los que ha cifrado el voto (por ejemplo, en caso del algoritmo de cifrado de ElGamal mostraría el valor aleatorio que ha usado para cifrar), para que el votante pueda comprobar que cifrando las opciones escogidas con los valores entregados por el cliente, el hash del resultado coincide con el compromiso dado. En caso de auditar el voto, éste se vuelve a cifrar con otros valores diferentes antes de ser enviado para que el votante no pueda usar los valores entregados por el método de verificación, para demostrar a un tercero cómo ha votado. El servidor de voto remoto dispone de una herramienta de publicación de los votos recibidos, normalmente conocida como bulletin board. Este bulletin board juega un papel muy importante en los protocolos de voto verificables. En [44] se explica que un bulletin board es un canal público donde los participantes autorizados pueden publicar datos, y, una vez publicados, no pueden ser ni borrados ni sobrescritos por nadie. Entonces, el votante puede comprobar que, en caso de decidir enviarlo, el voto cifrado al que el cliente de voto se había comprometido, antes de que el votante eligiera entre enviarlo o auditarlo, es el que ha recibido el servidor de voto. Como el cliente de voto se compromete al valor del voto cifrado antes de saber si el votante lo auditará o no, no puede comprometerse a un voto diferente al que enviará sin que haya un 50% de probabilidad de que el votante le descubra.
El problema de este sistema es que el votante necesita una herramienta para rehacer el cifrado de las opciones escogidas con los valores entregados por el cliente de voto retado, para comprobar que coincide con el valor comprometido. Además del problema de que los votantes entiendan el sentido de los números largos que se les muestra, claves públicas, aleatoriedad, etc., hay que entregar esta herramienta (que no podría ser una calculadora dada la longitud de los números para hacer los cálculos) de forma independiente al software del cliente de voto, para que no se pongan los dos de acuerdo para engañar al votante.
Otras propuestas de voto electrónico que implementa este tipo de verificación son VoteBox [60] y Wombat Voting [9].
VoteBox es un sistema de voto electrónico presencial, pensado para elecciones donde se vota utilizando máquinas de voto electrónico (también conocidas como Digital Recording Electronic voting machine, o DRE) en los colegios electorales.
El voto electrónico presencial es muy común en Estados Unidos. En este sistema, todos los DREs de un colegio electoral están conectados mediante una LAN (Local Area Network). Cuando el votante emite el voto, el voto cifrado se almacena en el DRE donde está el votante y se transmite a través de la LAN a los otros DREs, que también la almacenan. Una vez emitido el voto, si el votante quiere auditarlo, el DRE envía a través de la LAN los factores que ha utilizado en el cifrado. En el mismo colegio hay montado un dispositivo llamado diodo que pincha la LAN, de forma que se puede observar todo el tráfico de la red. Este diodo se utiliza para observar, tanto el voto cifrado que se ha enviado a todos los DREs, como los factores de cifrado que entrega el DRE en cuestión si el votante decide auditar su voto. Con los datos observados se puede verificar que el voto emitido se corresponde con el elegido por el votante. Una vez auditado, el voto almacenado en todos los DREs se anula para prevenir la venta de votos (similar al caso de Helios).
Wombat Voting es un sistema de voto presencial donde los votantes utilizan máquinas de votación para seleccionar sus opciones e imprimir sus votos en papel para depositarlos en una urna electoral. Estos votos (cifrados) son impresos en un formato de código de barras bidimensional (o QR), de forma que se puede utilizar un lector para digitalizar los votos y hacer el recuento de forma electrónica. De forma muy similar al sistema Helios, una vez el voto cifrado se imprime en papel, el votante puede decidir si auditar el voto, con lo que la máquina de votación entrega los valores del cifrado para comprobar que lo que había impreso es el cifrado de las opciones escogidas por el votante. Igual que en los otros sistemas, los votos auditados no pueden ir a la urna.
Son una de las funcionalidades de los protocolos Pollsterless de los que hablamos en la sección 2. La principal idea es que el servidor de voto remoto utiliza una clave secreta para generar nuevos valores a partir del voto cifrado que ha enviado el votante. Estos valores o códigos de retorno se envían al votante, que está en posesión de una tarjeta especial donde aparecen todas las opciones de voto posibles con los correspondientes códigos de retorno asignados (ver figura 12). Si los códigos recibidos se corresponden con los que en la tarjeta están asignados a las opciones escogidas, suponiendo que los códigos de retorno que hay en las tarjetas sólo son conocidos por los votantes, y que la clave del servidor de voto se mantiene secreta, el votante puede estar seguro de que las opciones cifradas recibidas en el servidor son las mismas que las que él ha escogido.
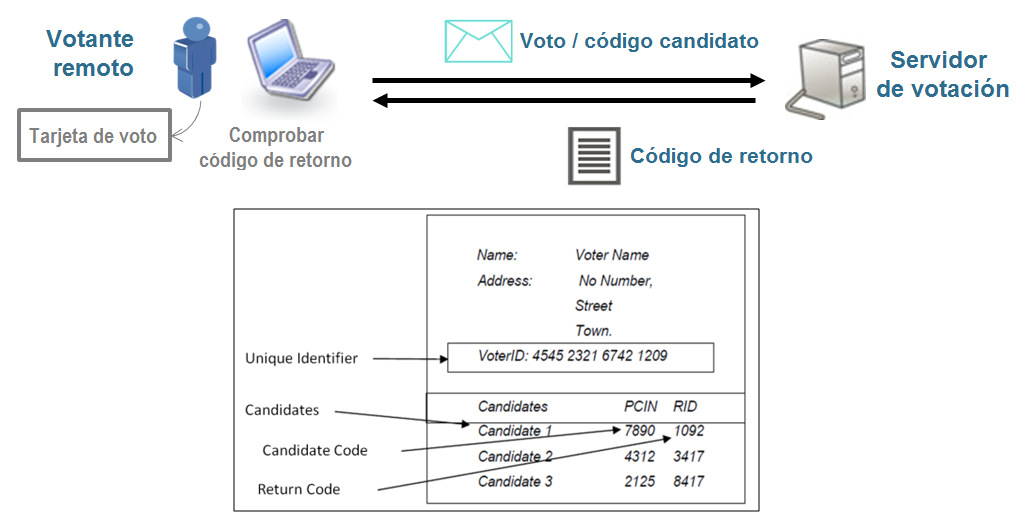
Como hemos visto en la sección anterior, los esquemas de Pollsterless utilizan dos tipos de códigos, uno de candidato u opción, que es el valor precifrado de la opción escogida que se envía al servidor de voto, y el código de retorno que envía el servidor como respuesta al votante. También existe la opción mixta de tener un cliente de votación que sea el que cifre las opciones escogidas (sin usar valores precifrados) y obtener unos códigos de retorno generados por el servidor como confirmación de estas opciones. En este caso, las tarjetas de los votantes solo tendrían códigos de retorno, y no códigos de candidato u opción. Esta variante del Pollsterless presenta algunas ventajas: los votantes no han de poner códigos para votar, sino compararlos para verificar, lo que comporta una gran mejora de la usabilidad del sistema. Además, estamos hablando de utilizar tarjetas en papel que han de ser distribuidas. Como ya se ha dicho, una de las ventajas del voto electrónico es poderse ahorrar toda la logística asociada al reparto de papeletas, voto postal etc. En un sistema Pollsterless puro, en caso de que las tarjetas no lleguen a tiempo a los votantes, estos no podrán votar. En caso de la opción mixta, los votantes podrán votar, pero no verificar, lo que puede considerarse un mal menor. Incluso podría ser que los votantes tuvieran las tarjetas antes de que acabe el periodo de votación, para poder verificar el voto que habían emitido en su momento y estar a tiempo de anularlo si el código de retorno no coincide con la opción escogida.
Para poder aplicar la funcionalidad de los códigos de retorno, es necesario que las opciones de voto se cifren con un algoritmo con propiedades deterministas, de manera que cuando el servidor de voto haga sus cálculos sobre estas opciones cifradas, usando su clave secreta, genere unos códigos de retorno que hayan podido ser calculados previamente a la fase de configuración de la elección, para generar las tarjetas de los votantes.
Obviamente, con un sistema de cifrado con propiedades aleatorizadoras, los valores no serían repetibles. Por otro lado, desearíamos que los votos emitidos al servidor de voto se hubieran cifrado con un algoritmo con propiedades aleatorizadoras para no poder saber si varios votantes han votado por la misma opción, o si un votante envía dos votos con el mismo contenido en caso de que se permita el voto múltiple (también para evitar coacción o venta de votos). Las opciones que se han propuesto hasta ahora pasan por tener un servidor de voto que sea capaz de quitar la capa de cifrado aleatorizador para generar los códigos de retorno [34], o para generar dos tipos de cifrado en el cliente [55], uno que puede destapar el servidor para tener unos valores deterministas sobre los que generar los códigos de retorno, y otro que no, y que es el que se hará llegar al proceso de recuento.
En el primer caso, el servidor de voto está dividido en dos componentes que, juntas, tienen la capacidad de descifrar los votos (podemos decir que cada uno tiene la mitad de la clave privada de la elección). Para proteger la privacidad de los votantes, la primera componente sacará la parte del cifrado aleatorizador correspondiente a su clave privada, pero añadirá una capa de cifrado determinista antes de pasar el resultado a la segunda componente, que sacará la segunda parte del cifrado aleatorizador. El principal inconveniente de esta solución es que si las dos componentes se ponen de acuerdo, pueden descifrar todos los votos y romper la privacidad de los votantes.
En el segundo caso, el cliente de votación hace dos cifrados de las mismas opciones: uno con un algoritmo con propiedades aleatorizadoras, usando la clave pública de la elección, y otro que en un primer paso se cifra con un algoritmo determinista, y después con un algoritmo con propiedades aleatorizadoras con la clave pública del servidor de votación. Así, el servidor de votación es capaz de sacar la capa aleatorizadora del segundo cifrado para obtener un valor determinista sobre el que generar el código de retorno, pero no puede ver cuál es la opción escogida por el votante (porque no puede sacar la capa del cifrado determinista). Se utilizan pruebas criptográficas para demostrar que los cifrados sobre los que se generan los códigos de retorno contienen las mismas opciones de voto que los otros cifrados, que son los que se procesan en la fase de recuento. Estas pruebas criptográficas son pruebas de conocimiento nulo que, igual que en el sistema de Mixing de credenciales de la sección 3, se utilizan para demostrar que dos cifrados se corresponden con el mismo texto en claro sin tener que mostrar los valores secretos (el valor o la opción de voto cifrada).
Los principales inconvenientes de esta solución son la usabilidad y el alto coste computacional que recae en el cliente de voto: el cliente de voto ha de cifrar cada opción de voto por separado, para poder generar un código de retorno independiente para cada una; como hemos explicado, no se hace un único cifrado, sino dos para cada opción de voto (uno sobre el que se genera el código de retorno y otro que va al recuento), lo que conlleva un gran número de operaciones por selección; la generación de pruebas criptográficas que relacionan un cifrado con el otro (para asegurar que tienen el mismo contenido) añade más operaciones al cliente de voto; finalmente, el cifrado con propiedades deterministas que hace el cliente de voto ha de utilizar algún secreto que solo conozca el votante, para evitar que el servidor descubra demasiada información al generar los códigos de retorno. La solución propuesta es que el votante introduzca un código único que viene con la tarjeta de los códigos de retorno, que se asuma que solo él la conoce. Como se ha explicado, esto va en contra del requisito de que el votante no haya de introducir códigos para verificar su voto.
Aunque mucha gente trabaja en el mismo problema, no se ha encontrado una solución óptima, sino que se elige la que tiene menos inconvenientes según el criterio que se establezca. Esto demuestra que aún hay mucho camino por recorrer.
Los sistemas de verificación que actúan en esta fase se aplican habitualmente en esquemas de voto electrónico donde se utilizan técnicas de recuento homomórfico o Mixnets, ya que son estos procesos que anonimizan los votos los que hay que auditar para asegurar que los resultados de la elección se corresponden con lo que han votado los votantes.
Se basan en la propiedad homomórfica del algoritmo utilizado para cifrar los votos, que hace que la operación de votos cifrados tenga como resultado el cifrado de la operación de los votos. Se usa esta propiedad para obtener el resultado de la elección de forma verificable de la siguiente manera (ver figura 13):
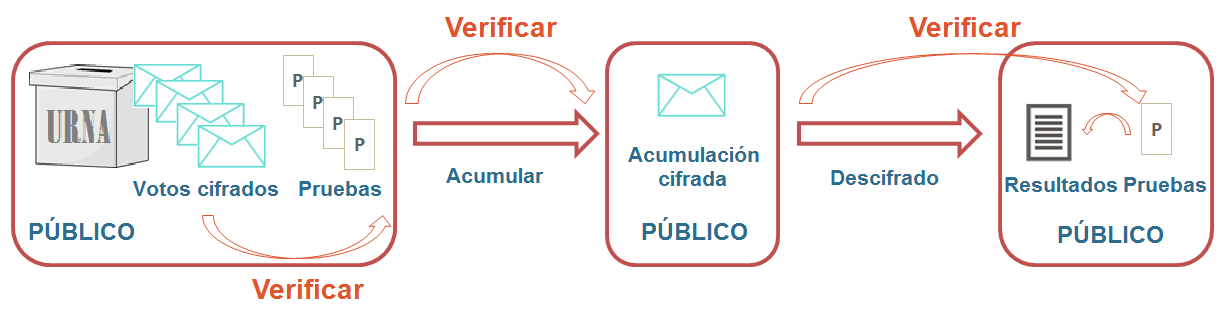
Una medida adicional en estos esquemas es que la clave privada de la elección no exista en ningún momento, ya que se podría utilizar para descifrar los votos individuales en lugar de los acumulados, rompiendo así la privacidad de los votantes. En lugar de esto, se usan medidas como las explicadas en la sección 1.6 para dividir la clave en trozos o shares que están repartidos entre los miembros de la mesa electoral siguiendo un esquema umbral, o incluso, generar los shares directamente sin que la clave privada haya existido nunca. En [23] se define un sistema de voto electrónico con recuento homomórfico, en el que cada miembro de la mesa electoral usa su parte de la clave privada para hacer un descifrado parcial del resultado de la operación de los votos, y genera una prueba de que este descifrado parcial es consistente con su parte de la clave. Esta información se publica en el bulletin board, así cuando el conjunto mínimo de la mesa electoral (según el umbral elegido) haya publicado sus operaciones, los valores de los diferentes descifrados parciales se podrán combinar de forma pública para obtener el resultado.
Los esquemas de recuento homomórfico son muy adecuados para proporcionar propiedades de verificabilidad, ya que casi todas las operaciones se pueden hacer de forma pública y, para las que no (descifrados parciales, etc.), se pueden proporcionar pruebas universalmente verificables que demuestren que se han hecho bien. Por universalmente verificables entendemos que, al no requerir de datos secretos para hacer su validación, pueden ser verificadas por cualquiera. No obstante, los inconvenientes de estos esquemas, comentados en la sección 2, hacen que sean poco flexibles y costosos en general.
Como hemos explicado en la sección 2, son procesos en que varios nodos colaboran para, de forma secuencial, mezclar y recifrar o descifrar los votos con el objetivo de eliminar la relación entre el votante que ha emitido el voto y el voto en claro. La Mixnet ha de actuar como una caja negra y la permutación y los valores de recifrado o descifrado han de mantenerse en secreto para evitar romper la privacidad del votante, ya que el propósito de la Mixnet es que no se puedan conectar los votos a la salida con los votos a la entrada (que se pueden relacionar con los votos firmados emitidos por los votantes), pero esto también tiene el inconveniente de que no podemos asegurar la correspondencia entre los votos de entrada y de salida a efectos de conocer que la mixnet no ha modificado, añadido o eliminado votos. La solución clásica pasa por ejecutar la mixnet en un entorno aislado y con un código auditado [57]. No obstante, el propósito de la verificabilidad es no tener que fiarnos del software ni de la plataforma, sino que el proceso proporcione unas pruebas de que ha actuado de forma honesta, que no se puedan falsificar y que todo el mundo pueda validar. Desde la Mixnet verificable de Sako y Kilian [59] han surgido muchas propuestas para la generación en cada nodo de la mixnet de pruebas que demuestren que el conjunto de votos a la salida es el recifrado o el descifrado de los de entrada permutados (ver figura 14). Un buen compendio de estas propuestas se encuentra en [10], y básicamente se pueden dividir entre propuestas de verificación heurística y propuestas de verificación exhaustiva.
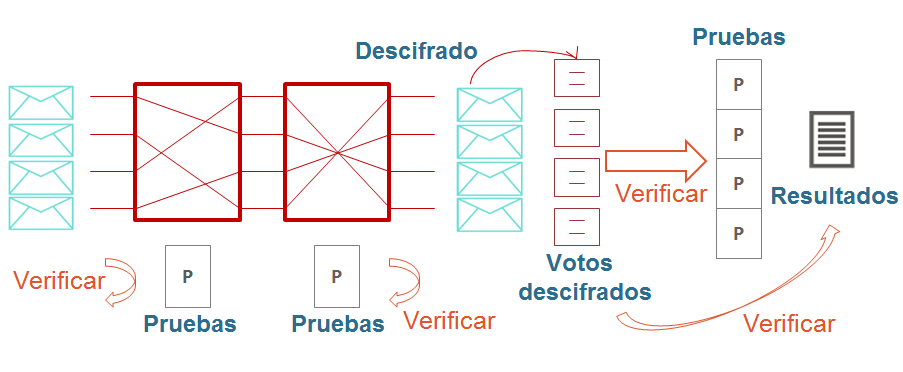
En las propuestas de verificación heurística los nodos de la mixnet generan pruebas criptográficas que aseguran, con una cierta probabilidad, que la mixnet no está actuando de forma fraudulenta. Estas propuestas se basan generalmente en hacer pruebas de conocimiento nulo que demuestran que un voto a la salida del nodo es el recifrado o el descifrado de un voto a la entrada de este nodo. Por la naturaleza de estas pruebas, no es necesario conocer datos secretos de la mixnet (permutación y factores de recifrado o descifrado), así que el proceso puede considerarse universalmente verificable. Como mostrar esta relación entre entrada y salida rompe con el propósito de la mixnet de no proporcionar rastreabilidad, existen varias propuestas para generar las pruebas de diferentes maneras, de las cuales explicamos las más significativas:
Se habla de propuestas de verificación heurística porque, dependiendo de cómo se generen las pruebas que relacionan votos de entrada y de salida para mantener la privacidad, la mixnet tiene una cierta probabilidad de hacer trampas y modificar votos sin ser detectada, aunque esa probabilidad es muy reducida.
Algunas de estas propuestas se habían roto hace un tiempo (como [35, 67]), es decir, se han encontrado ataques para los que la probabilidad de la mixnet de engañar no era tan pequeña como se creía. Pero recientemente Douglas Wikström ha publicado dos artículos en que propone ataques para otros esquemas de este tipo, uno para el Random Partial Checking [41] y otro para la propuesta [54], en [40]. Aunque no es fácil llevar a la práctica los ataques propuestos, (se tendrían que poner de acuerdo un volumen considerable de votantes y, al menos, el primer nodo de la mixnet), estas publicaciones han afectado de forma considerable a la credibilidad de los sistemas de verificación heurística.
Las propuestas basadas en sistemas de verificación heurística surgieron como contrapartida a las propuestas de verificación exhaustiva, porque éstas, para dar un cierto nivel de certeza más alto, de que la mixnet no puede mentir, necesitan de la generación de pruebas criptográficas muy costosas e incluso inasumibles en el caso de gran volumen de votos. Hasta hace unos años, la propuesta de verificación exhaustiva más eficiente era la de Andy Neff [48]. Pero recientemente, el trabajo de Jens Groth [14] y de Douglas Wikström [65, 68] en este tema, ha proporcionado muchas mejoras en la eficiencia de estos sistemas.
En este apartado sólo hemos hablado de la verificación del proceso de mixing, pero hay que tener en cuenta que algunas de las herramientas que se han presentado para los esquemas de recuento homomórfico, como el bulletin board para publicar los votos recibidos en el servidor de voto, y la generación y publicación de pruebas de descifrado o descifrado parcial cuando los miembros de la mesa descifran los votos, también se pueden aplicar en escenarios de votación donde se usan mixnets para proteger la privacidad de los votantes, para permitir a votantes y observadores verificar que los votos han sido emitidos por votantes válidos y que el proceso de descifrado ha sido correcto.
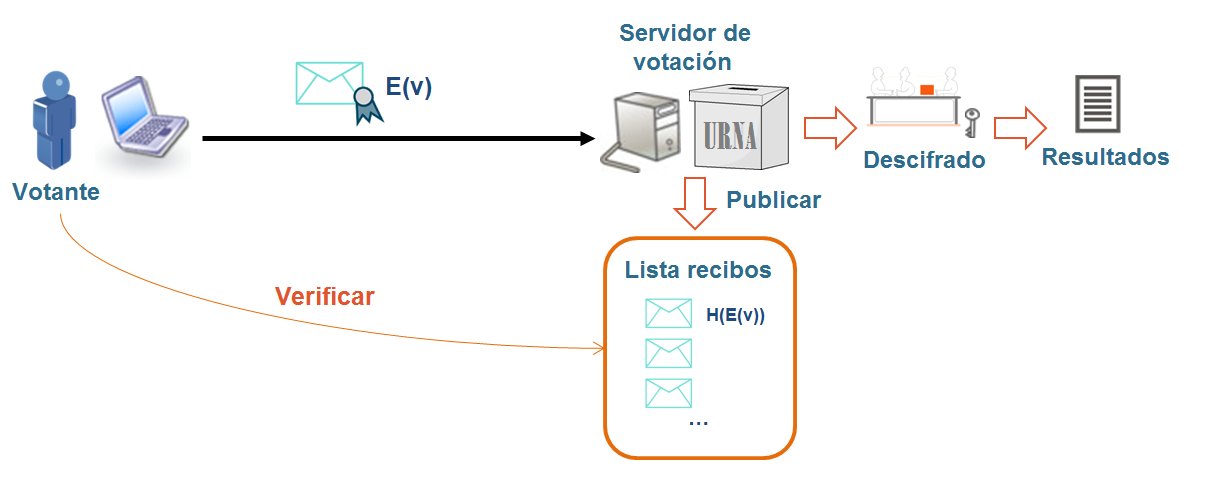
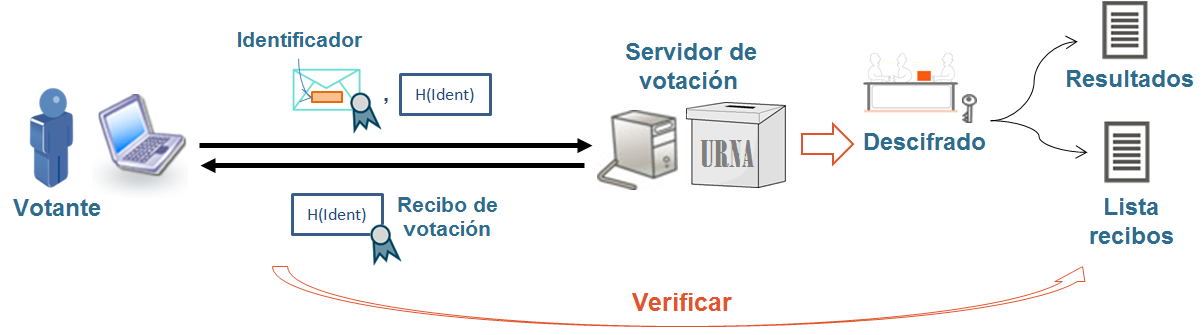
Los recibos de votación son unos valores que se generan a partir de un voto, una vez recibido en el servidor de voto, se devuelven al votante, y se utilizan para que el votante pueda buscar este valor dentro de una lista para comprobar que su voto está en el servidor de voto (ha llegado) hasta una determinada fase del proceso. Dependiendo del tipo de recibo, la verificación se aplica en diferentes fases: